go-网络爬虫

1 网络爬虫是何物?
说道网络爬虫,然后它并不是一种爬虫,而是一种可以在网上任意搜索的一个脚本程序。
有人说一定要结束网络爬虫到底是干毛用的。
尝试用了很多种解释,最终归纳为一句话。
“你再也不必用鼠标一条一条从网页上拷贝信息了!”
一个爬虫程序将会高效并且准确的从网上拿到你希望得到的所有信息,从而帮我们省去以下行为:
while (no_dead) {
寻找网页
鼠标点击
ctrl-c
ctrl-v
翻页
}
当然网络爬虫的真正意义不仅如此,由于它可以自动提取网页信息,使他成为了 搜索引擎 从
万维网上下载网页的重要利器。下面我们来介绍一下网络爬虫的正经定义。

网络爬虫 (web Spider),Spider是蜘蛛的意思,实际上名字是很形象的,他们把 互联网 比喻
成一个 蜘蛛网 ,那么所谓的这个spider就在网上爬来爬去。这个网络蜘蛛是通过网页的链接
地址来寻找网页的。
蜘蛛的主要行径: 网页首页—>读取网页内容—>找到网页中其他的链接地址—>其他网页的
首页—>……这样的循环下去,直到将这个网站上所有的网页都吃光(网页上所有的信息全部用蜘蛛得
到)。
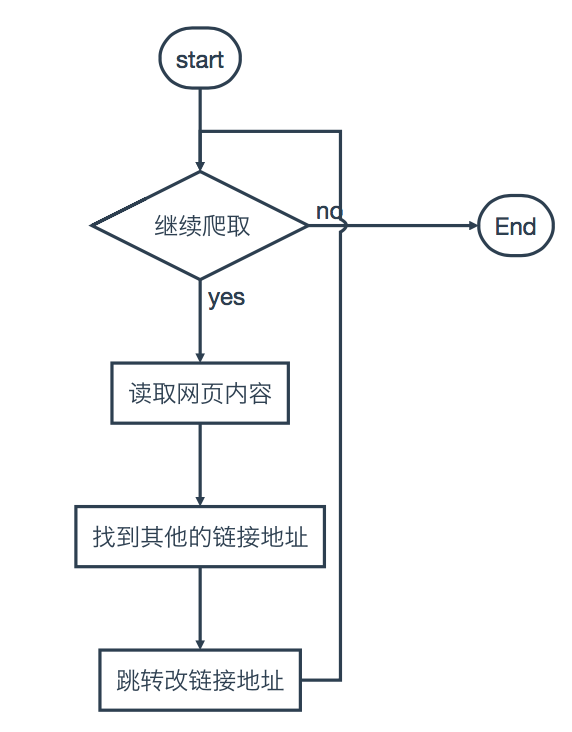
这样的循环下去,直到将这个网站上所有的网页都吃光(网页上所有的信息全部用蜘蛛得
到)。如果你敢把互联网比喻成一个网站,一定会有那么一个网络蜘蛛能够可以把 整个互联网 的资
源全部吃光!!
ok,那么显而易见,网络爬虫的基本操作就是抓取网页。网页地址就是一个叫URL的东西,
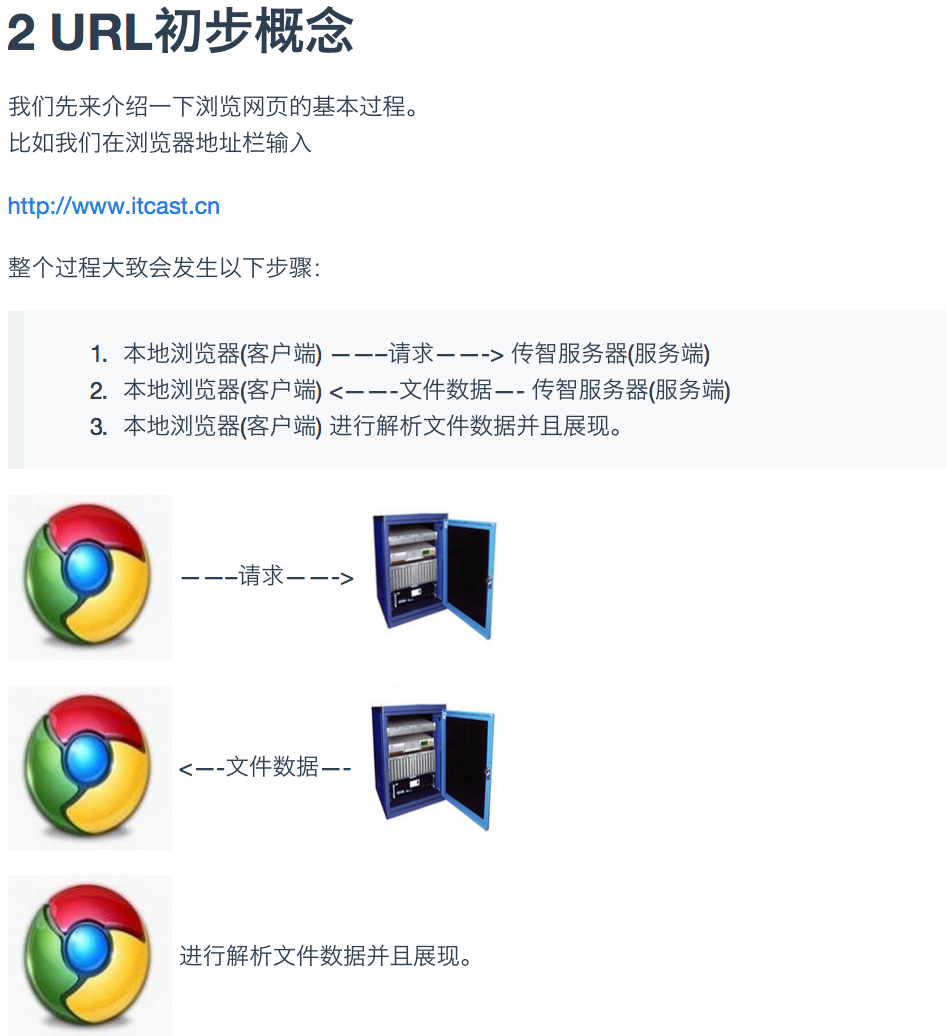
那么实际上浏览器用的是一种叫html标记的语言来进行解析的。
html标记语言 :http://www.w3school.com.cn/
ok,那么到底谁是URL呢,说了半天, http://www.itcast.cn
它!就是URL!没错,就是它!
我们给浏览器输入的地址,实际上就是一个url(Uniform Resource Locator) 统一资源定位符 。
就是 地址 啦,搞学术的人非得弄的很高端。
明明是高利贷,他们非得说成p2p,明明是算命的,他们非得说成分析师~
URL的一般格式是: protocol:// hostname[:port] / path / [;parameters][?query]#fragment
基本上是由三部分组成:
1 协议(HTTP呀,FTP呀~~等等)
2 主机的IP地址(或者域名)
3 请求主机资源的具体地址(目录,文件名等)
其中:
第一部分和第二部分用 “://” 分割
第二部分和第三部分用 “/” 分割
1://2/3 —–>http://www.itcast.cn/channel/teacher.shtml#ac
下面看几个URL例子:
http://xianluomao.sinaapp.com/game
其中
协议: http,
计算机域名: xianluomao.sinaapp.com,
请求目录:game
http://help.qunar.com/list.html
其中
协议:http,
计算机域名:help.qunar.com
文件:list.html
网络爬虫的主要处理对象就是类似于以上的URL,爬虫根据URL地址取得所需要的文件内容,然后对它进一步的处理。
3 Go语言发送 http请求?
package main
import "fmt"
import "net/http"
import "io/ioutil"
func httpGet(url string) (content string, statusCode int) {
//发送http.Get方法请求远程url
resp, err := http.Get(url)
if err != nil {
fmt.Println(err)
statusCode = -100
return
}
//关闭网络通信文件
defer resp.Body.Close()
//通过ioutil库从服务器得到返回的结果
//data 即为 返回的网络数据
data, err := ioutil.ReadAll(resp.Body)
if err != nil {
fmt.Println(err)
statusCode = resp.StatusCode
return
}
//content为网络数据
content = string(data)
//statusCode为返回的http 状态值
statusCode = resp.StatusCode
return
}
func main() {
content, rcode := httpGet("http://www.baiduhuaidan.com")
fmt.Println("content = ", content)
fmt.Println("rocde = ", rcode)
}
4 go语言实现百度贴吧小爬虫
package main
import (
"fmt"
"io/ioutil"
"net/http"
"os"
"strconv"
)
//第1页:https://tieba.baidu.com/f?kw=lol&ie=utf-8&pn=0
//第2页:https://tieba.baidu.com/f?kw=lol&ie=utf-8&pn=50
//第3页:https://tieba.baidu.com/f?kw=lol&ie=utf-8&pn=100
//第4页:https://tieba.baidu.com/f?kw=lol&ie=utf-8&pn=150
func httpGet(url string) (content string, statusCode int) {
resp, err := http.Get(url)
if err != nil {
fmt.Println(err)
statusCode = -100
return
}
defer resp.Body.Close()
data, err := ioutil.ReadAll(resp.Body)
if err != nil {
fmt.Println(err)
statusCode = resp.StatusCode
return
}
content = string(data)
statusCode = resp.StatusCode
return
}
//主业务爬取函数
func spider_tieba(begin_page int, end_page int) {
var pn int
fmt.Println("准备爬取从 ", begin_page, " 到 ", end_page, " 页")
for page := begin_page; page < end_page+1; page++ {
fmt.Println("正在爬取 第", page, "页")
//明确目标
pn = (page - 1) * 50
url := "https://tieba.baidu.com/f?kw=lol&ie=utf-8&pn=" + strconv.Itoa(pn)
fmt.Println("url=", url)
//开始爬取
content, rcode := httpGet(url)
if rcode < 0 {
fmt.Println("httpGet error, rcode = ", rcode, "page = ", page)
continue
}
//处理数据(把数据保存在本地文件中)
filename := strconv.Itoa(page) + ".html"
if f, err := os.Create(filename); err == nil {
//打开文件成功
f.WriteString(content)
f.Close()
}
}
}
func main() {
var begin_page string
var end_page string
fmt.Println("请输入要爬取的起始页码")
fmt.Scanf("%s\n", &begin_page)
fmt.Println("请输入要爬取的终止页码")
fmt.Scanf("%s\n", &end_page)
b, _ := strconv.Atoi(begin_page)
e, _ := strconv.Atoi(end_page)
spider_tieba(b, e)
}